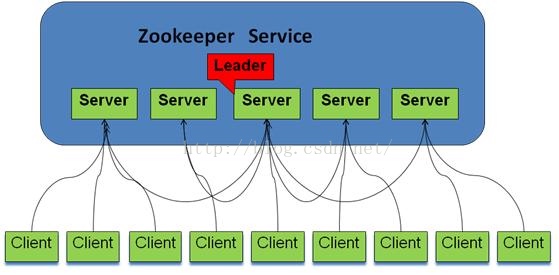
一、什么是Zookeeper
ZooKeeper是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
它的核心是:文件系统 + 通知机制
二、重要特点
- 一个领导者(Leader),多个跟随者(Follower)组成的集群
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务
- 全局数据一致性,每个server保存一份相同的副本,client无论链接哪个server,得到的数据都是一致的
- 更新请求顺序执行,来自同一个client的请求按顺序执行
- 数据更新原子性,一次数据更新要么成功要么失败
- 实时性,在一定时间范围内,client能读到最新数据
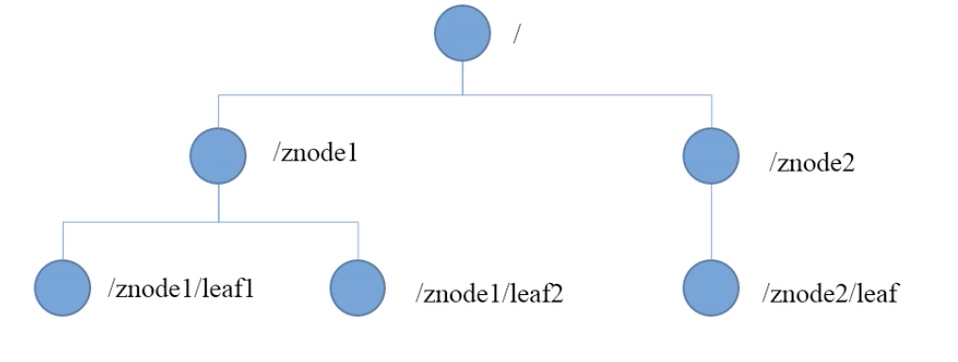
三、数据结构
Zookeeper数据模型的结构与Unix文件系统很类似,整体上可看作是一棵树,每个节点称作一个ZNode。每个ZNode默认能存储1MB数据,每个ZNode都可以通过其路径唯一标识。
四、应用场景(※)
- 分布式锁
- 服务注册和发现
- 利用Znode和Watcher,可以实现分布式服务的注册和发现。最著名的应用就是阿里的分布式RPC框架Dubbo。
- 共享配置和状态信息
- Redis的分布式解决方案Codis(豌豆荚),就利用了Zookeeper来存放数据路由表和 codis-proxy 节点的元信息。同时 codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy。
五、选举机制(※)
5.1 半数机制(paxos协议)
集群中半数以上机器存活,集群可用,所以Zookeeper适合安装奇数台服务器
5.2 内部选举
在分布式系统中选主最直接的方法是直接选定集群的一个节点为leader,其它的节点为follower,这样引入的一个问题是如果leader节点挂掉,整个集群就挂掉了。需要有一种算法自动选主,如果leader节点挂掉,则从follower节点中选出一个主节点。
1. 选举阶段 Leader election
最大ZXID也就是节点本地的最新事务编号,包含epoch和计数两部分。epoch是纪元的意思,相当于Raft算法选主时候的term,标识当前leader周期,每次选举一个新的Leader服务器后,会生成一个新的epoch
- 所有节点处于Looking状态,各自依次发起投票,投票包含自己的服务器ID和最新事务ID(ZXID)。
- 如果发现别人的ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
- 每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为准Leader,状态变为Leading。其他节点的状态变为Following。
2. 发现阶段 Discovery
- 为了防止某些意外情况,比如因网络原因在上一阶段产生多个Leader的情况。
- Leader集思广益,接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
- 各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史事务日志。Leader选出最大的ZXID,并更新自身历史日志。
3. 同步阶段 Synchronization
Leader刚才收集得到的最新历史事务日志,同步给集群中所有的Follower。只有当半数Follower同步成功,这个准Leader才能成为正式的Leader。
六、ZNode 内构
6.1 节点类型
持久persistent:client 和 server 断开连接后,创建的节点不删除
短暂ephemeral:client 和 server 断开连接后,创建的节点自己删除
另外分 有序和无序。创建有序节点时,会自动将节点名增加序列号
1 | $ create -s /test/no1 "no1" |
6.2 内部结构
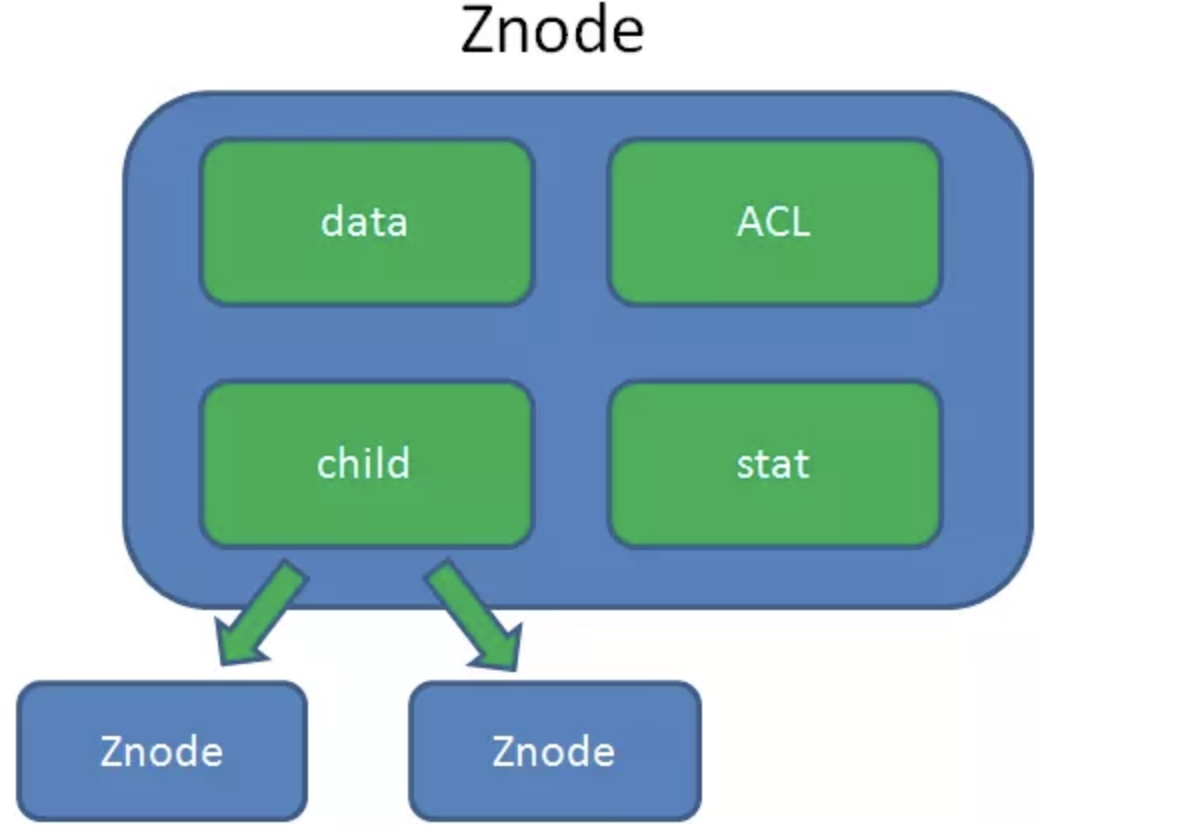
- data: ZNode存储的数据信息,每个节点数据最大不超过1MB
- ACL(Access Control List): 记录访问权限,哪些人或哪些IP可访问本节点
- child: 当前节点的子节点
- stat: 各种元数据,比如事务ID、版本号、时间戳、大小等
- czxid- 引起这个 znode 创建的 zxid,创建节点的事务的 zxid
- ctime - znode 被创建的毫秒数
- mzxid - znode 最后更新的 zxid
- mtime - znode 最后修改的毫秒数
- pZxid-znode 最后更新的子节点 zxid
- cversion - znode 子节点变化号,znode 子节点修改次数 7)dataversion - znode 数据变化号
- aclVersion - znode 访问控制列表的变化号
- ephemeralOwner- 如果是临时节点,这个是znode拥有者的 session id。如果不是临时节点则是 0
- dataLength- znode 的数据长度
- numChildren - znode 子节点数量
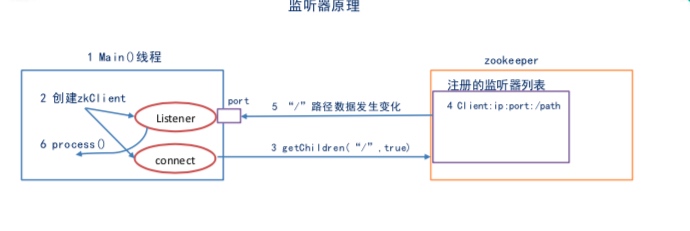
七、监听器原理(※)
| 客户端 | 服务端 |
|---|---|
| Main进程 | |
| 创建ZK客户端,会创建connet网络连接通信线程,listener监听线程 | |
| 通过connect线程将注册的监听事件发送给Zookeeper服务端 | |
| 将监听事件添加到注册监听器列表 | |
| 监听到有数据或路径变化,将消息发送给listener | |
| listener线程内部调用process方法 |
八、常见监听
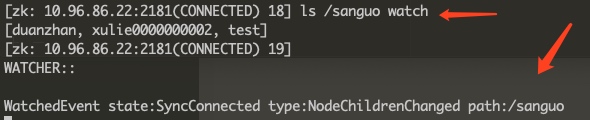
- 子节点增减变化(如下示例)
- 节点数据变化

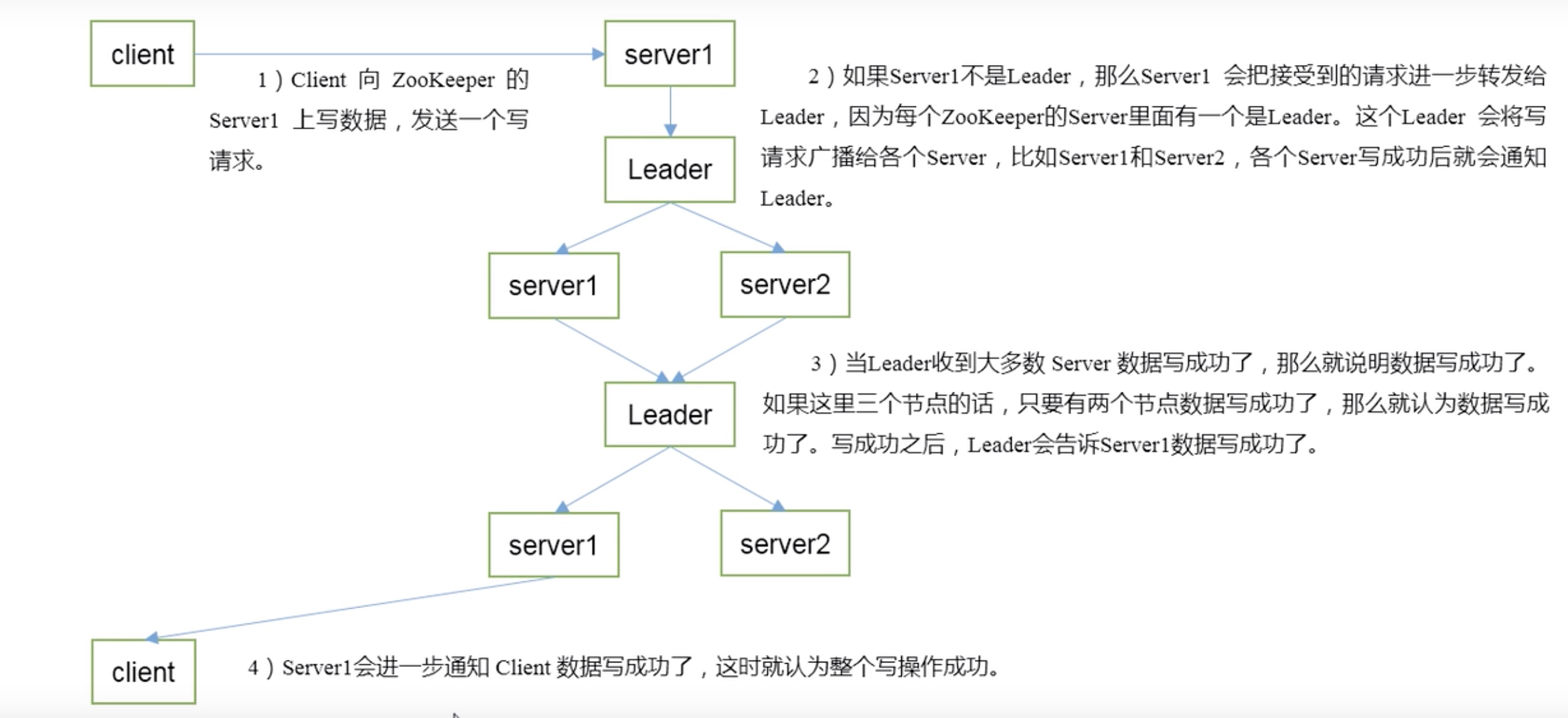
九、写数据流程
- 客户端发出写入数据请求给任意Follower。
- Follower把写入数据请求转发给Leader。
- Leader采用二阶段提交方式,先发送Propose广播给Follower。
- Follower接到Propose消息,写入日志成功后,返回ACK消息给Leader。
- Leader接到半数以上ACK消息,返回成功给客户端,并且广播Commit请求给Follower
十、命令
客户端连接
zkcli -server host:port
create [-s] [-e] path data acl
1 | $ create /test "data" |
get path [watch] watch指是否监听
1 | [zk: 10.96.86.22:2181(CONNECTED) 10] get /test |
更多
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
addauth scheme auth
quit
getAcl path
close
connect host:port
参考
https://juejin.im/post/5b037d5c518825426e024473
https://www.bilibili.com/video/av32093417/
https://blog.csdn.net/u013679744/article/details/79222103
《从Paxos到ZooKeeper》经典


