面试题:TCP三次握手
面试官:你知道TCP握手多少次吗?为什么?
我:三次握手,emm…因为他们感情好吧
面试官:好的,回去等消息吧。
TCP三次握手和四次挥手的流程,为什么断开连接要4次,如果握手只有两次,会出现什么
三次握手
A: “你听得到我吗”
B: “听得到呀,你听得到我吗”
A: “恩,听得到,balabala~”
四次挥手
A: “我没话说了”
B: “好”
B: “那我拜拜了,关门了”
A: “你关吧”
A.. 逗留一会(2msl),确认B不再开门说话了也关门了
【Golang进阶】定时器
Ticker
1. 用时间阻塞主程序,从而控制ticker
1 | func main() { |
输出结果
ticker1 at 2019-05-21 14:57:56.562591 +0800 CST m=+1.005065934
ticker1 at 2019-05-21 14:57:57.562549 +0800 CST m=+2.005016651
ticker1 at 2019-05-21 14:57:58.558122 +0800 CST m=+3.000583914
ticker1 at 2019-05-21 14:57:59.563205 +0800 CST m=+4.005660201
ticker1 at 2019-05-21 14:58:00.562585 +0800 CST m=+5.005033303
2. 用channel来精准控制次数
1 | func main() { |
输出结果
ticker2 at 2019-05-21 14:57:55.65885 +0800 CST m=+0.101330668
ticker2 at 2019-05-21 14:57:55.758399 +0800 CST m=+0.200878747
未命名
#
来自v2ex
1.Redis 常见问题( 100%)
数据结构,与 memcached 的区别,线程,io 多路复用( select,poll,epoll )
2.zookeeper ( 100%)
用法,分布式锁,zab 协议
3.MySQL 常见问题( 100%)
存储引擎,锁,隔离级别
4.计算机网路(全程抱着电脑边查边问):
tcp 四次挥手(简单的说了下 FIN 和 ACK )
问什么时候关闭连接? closewait 和 timedwaited 发生在哪里(一开始没说对,在引导下说出)
tcp 和 UDP 的区别( 100%)
网络分层每一层具体是什么(我回答没记住只记得最上层应用层,最下层物理层,HTTP→TCP/ UDP→IP )
DNS 是什么(忘了,真忘了😂,我都佩服我自己这忘了)
什么是一条连接,如何确定一条连接( emmm,根据连接 id ?被怼)
长连接和短连接的区别(不太了解)
【Golang零基础入门】07 Channel
channel 是goroutine的通道,所以不能直接在非goroutine里直接进行操作,否则会报错,例如
1 | c := make(chan int) |
var i chan int // 双向channel
var i chan<- int // 单向,只能收数据
i <- 1 // 这是允许的
j <- i // 这是不允许的
var i <-chan int // 单向,只能发数据
buffer channel
buffer可以减少goroutine的切换,例如下面,创建了3buffer的channel,在往channel写数据时,前3个写入都是会存储到buffer,但是写第4个的时候,会发现报错,fatal error: all goroutines are asleep - deadlock!,因为buffer已满,没有goroutine处理该channel数据。所以如果是没有buffer的channel,每次写入都会有一次goroutine的切换。
1 | func bufferChannel() { |
channel close
1 | func worker(c chan int) { |
不要通过共享内存来通信,通过通信来共享内存
这篇文章里面说的比较清楚了,使用共享内存的话在多线程的场景下为了处理竞态,需要加锁,使用起来比较麻烦。另外使用过多的锁,容易使得程序的代码逻辑坚涩难懂,并且容易使程序死锁,死锁了以后排查问题相当困难,特别是很多锁同时存在的时候。
go语言的channel保证同一个时间只有一个goroutine能够访问里面的数据,为开发者提供了一种优雅简单的工具,所以go原生的做法就是使用channle来通信,而不是使用共享内存来通信。
http://legendtkl.com/2017/07/30/understanding-golang-channel/

【MySQL 原理】02 索引原理与实现(二)
回顾

上一篇文章《MySQL索引为什么要用B+树》讲了MySQL为什么选择用B+树来作为底层存储结构,提了两个知识点:
- B+树索引并不能直接找到行,只是找到行所在的页,通过把整页读入内存,再在内存中查找。
- 索引的B+树高度一般为2-4层,查找记录时最多只需要2-4次IO。
为进一步知其所以然,今天来聊聊B+树索引在物理磁盘上是怎么设计存储的。
一、理解为什么要减少磁盘IO次数
众所周知,MySQL的数据实际是存储在文件中,而磁盘IO的查找速度是要远小于内存速度的,所以减少磁盘IO的次数能很大程度的提高MySQL性能。
1.1 磁盘IO为什么慢
先温习下知识点:磁盘IO时间 = 寻道 + 磁盘旋转 + 数据传输时间
从磁盘读取数据时,系统会将逻辑地址发给磁盘,磁盘将逻辑地址转换为物理地址(哪个磁道,哪个扇区)。
磁头进行机械运动,先找到相应磁道,再找该磁道的对应扇区,扇区是磁盘的最小存储单元(见图1-1)。
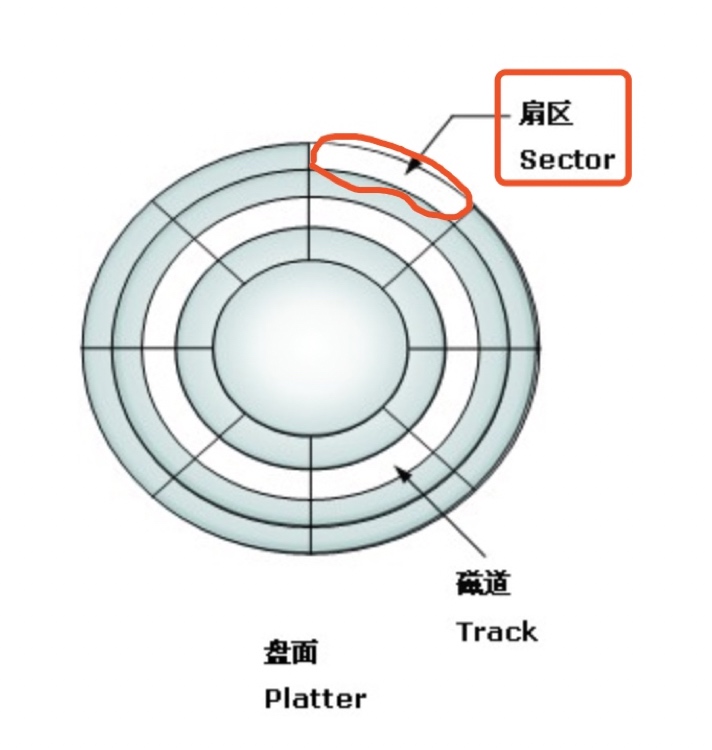
图1-1 磁盘物理结构
1.2 性能对比
机械硬盘的连续读写性能很好,但随机读写性能很差。
- 顺序访问:内存访问速度是硬盘访问速度的6~7倍(
kafka的特点,以后有机会的话再讲一讲) - 随机访问:内存访问速度就要比硬盘访问速度快上10万倍以上
随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上。
而在实际的磁盘存储里,是很少顺序存储的,因为这样的维护成本会很高。
二、索引在磁盘上的存储
知道磁盘IO的性能了吧,接下来看看MySQL是如何根据这种情况来设计索引的物理存储,以下内容以InnoDB引擎为例,MyISAM略有不同,后面再讲。
假设我们有一张这样的表,表中有如图2-0的数据
1 | CREATE TABLE `user` ( |
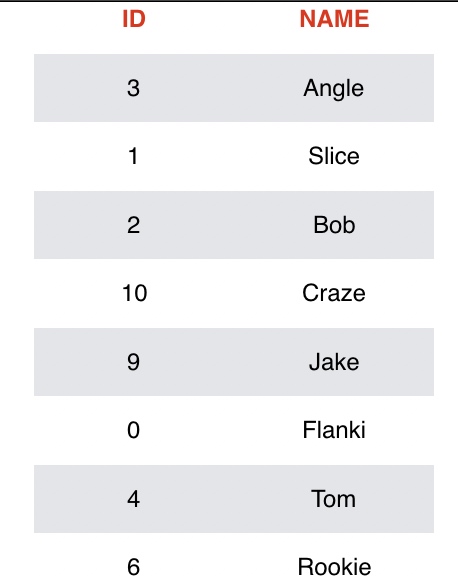
图2-0 表数据
2.1 聚集索引(Clustered index )
每个InnoDB表都有一个称为聚集索引的特殊索引,该索引是按照表的主键构造的一棵B+树。
根据示例数据构建如图2-1所示聚集索引:
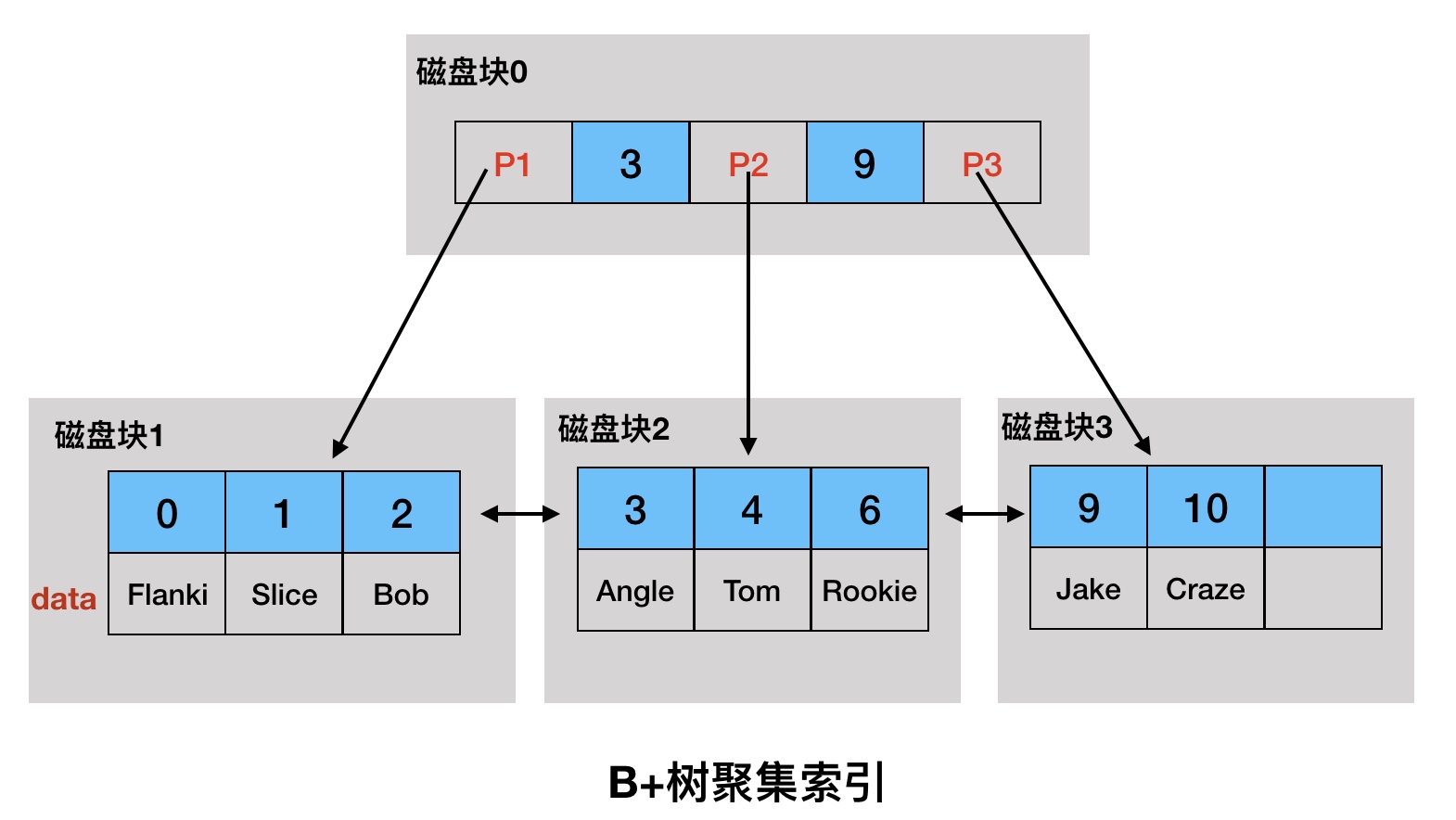
图2-1 B+树聚集索引
2.1.1 知识点
- 叶子节点存放了整张表的所有行数据。
- 非叶子节点并不存储行数据,是为了能存储更多索引键,从而降低B+树的高度,进而减少IO次数。
- 聚集索引的存储在物理上并不是连续的,每个数据页在不同的磁盘块,通过一个双向链表来进行连接。
2.1.2 查找:假设要查找数据项6
- 把根节点由磁盘块0加载到内存,发生一次IO,在内存中用二分查找确定6在3和9之间;
- 通过指针P2的磁盘地址,将磁盘2加载到内存,发生第二次IO,再在内存中进行二分查找找到6,结束。
这里只进行了两次IO,实际上,每个磁盘块大小为4K,3层的B+树可以表示上百万的数据,也就是每次查找只需要3次IO,所以索引对性能的提高将是巨大的。

2.1.3 怎样选择聚集索引
每张InnoDB表有且只有一个聚集索引,那它是怎么选择索引的呢?
- 一般情况,用
PRIMARY KEY来作为聚集索引。 - 如果没有定义
PRIMARY KEY,将会用第一个UNIQUE且NOT NULL的列来作为聚集索引。 - 如果表没有合适的
UNIQUE索引,会内部根据行ID值生成一个隐藏的聚簇索引GEN_CLUST_INDEX。
所以在建表的时候,如果没有逻辑唯一且非空列时,可以添加一个auto_increment的列,方便建立一个聚集索引。
2.2 非聚集索引(Secondary indexes)
非聚集索引又叫辅助索引,叶子节点并不包含行记录数据,而是存储了聚集索引键。
根据示例数据(idx_name索引)构建如图2-2所示辅助索引:
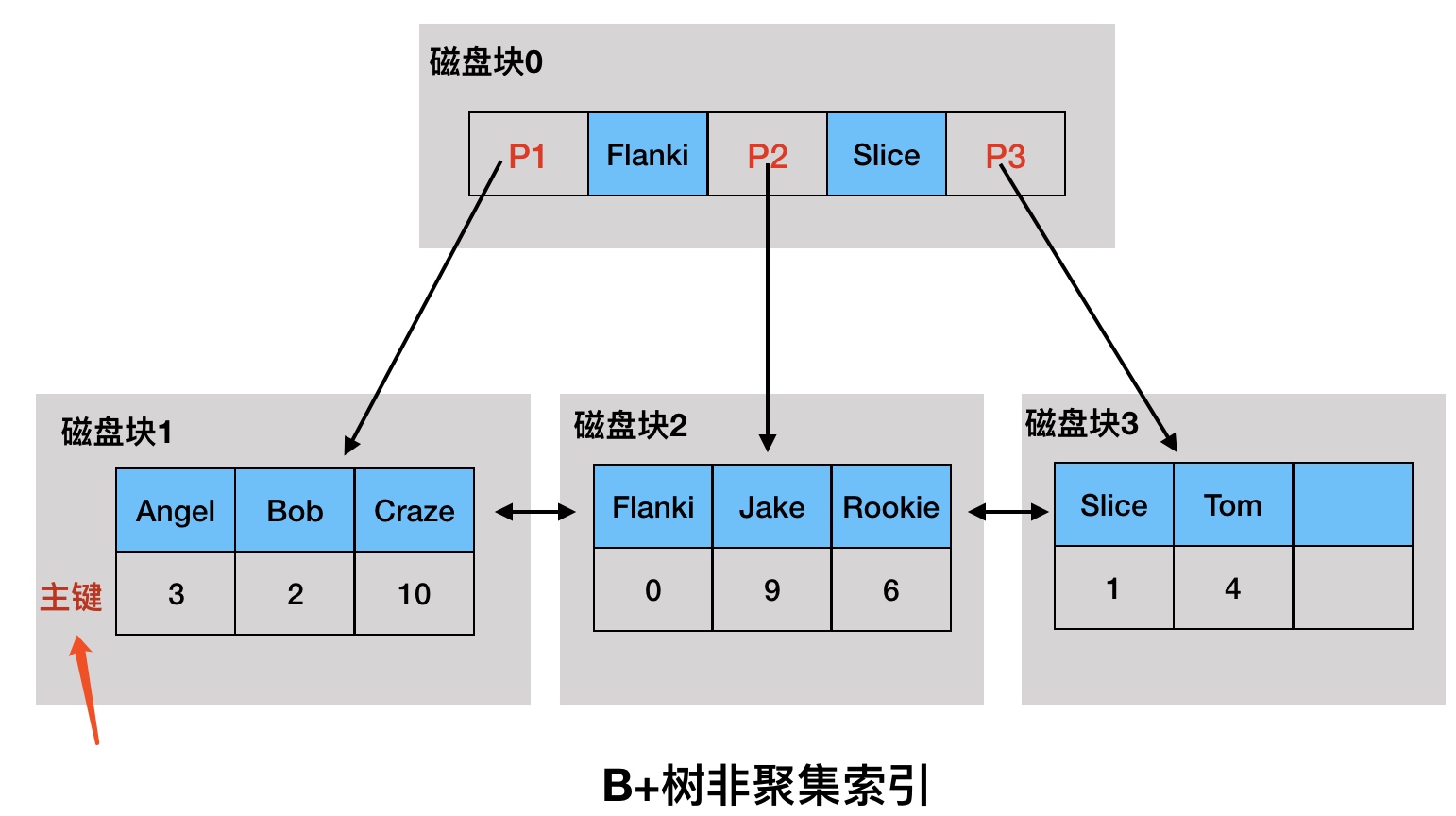
图2-2 B+树非聚集索引
2.2.1 知识点
- 每个表可以有多个辅助索引
- 通过辅助索引查数据时,先查找辅助索引获得聚集索引的主键,然后通过主键索引来查找完整的行记录。
- 通过非主键索引比主键索引查找速度要慢一倍。
2.2.2 查找:获取NAME=Jake的数据
第一阶段:通过辅助索引查到主键索引的主键
- 把idx_name索引的根节点由磁盘块0加载到内存,发生一次IO,查找到在P2指针中
- 根据P2指针的磁盘地址,加载磁盘块2到内存,发生第二次IO,查找到Jake节点以及它的主键索引9
第二阶段:通过主键索引找到完整的行记录
- 把根节点由磁盘块0加载到内存,发生一次IO,在内存中用二分查找确定9在P3指针中
- 通过指针P3的磁盘地址,将磁盘3加载到内存,发生第二次IO,再在内存中进行二分查找找到9,以及它的行记录,
查找结束。

未完待续…
【MySQL 原理】03 事务的隔离级别
一、事务
事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。 –摘自百度百科
知识点:在MySQL里,事务是在引擎层面实现,比如MyIsam不支持,InnoDB支持。

二、ACID
提到事务,肯定会想到 ACID 是吧,自行感受一下概念,然后我们来讲讲隔离性的问题。
原子性(
Atomicity):事务的所有操作要么全部成功,要么全部回滚。一致性(
Consistency):总是从一个一致性的状态转换到另一个一致性的状态。隔离性(
Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行持久性(
Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
三、隔离级别
脏读、幻读、不可重复读,做了多年的 CRUDer,对这几个词真是不陌生,要不是出去面试,也真不会去了解。希望大家看完之后,面试的时候,不要慌,跟他刚。
实际上,这些场景都是出现在多个事务同时执行时的场景。
3.1 脏读(Read Uncommitted)
通俗的讲,一个事务在处理过程中读取了另外一个事务未提交的数据。
你都还没提交呢,我怎么就读到了你刚操作的数据,万一你回滚了怎么办,你说这脏不脏。
举例:
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | Begin | |
| 2 | Begin | |
| 3 | select balance from account where id=1;(结果为1) | |
| 4 | update account set balance=2 where id=1; | |
| 5 | select balance from account where id=1;(结果为2) |
假设打赏的逻辑是:① 我的账户+1元;② 你的账户-1元。
当你执行到第一个步骤,我去查询我的账户已经是2元了,很开心!!!宣布请大家去撸串!!!
但是最后扣款的时候发现你余额不足了,回滚了,我的1元没了,就很难受!!!

3.2 不可重复读(Non-repeatable Read)
通俗的讲,一个事务范围内,多次查询某个数据,却得到不同的结果。
与脏读的区别:脏读是读到未提交的数据,而不可重复读读到的却是已经提交的数据,但实际上是违反了事务的一致性原则。
举例:
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | Begin | |
| 2 | Begin | |
| 3 | select balance from account where id=1;(结果为1) | |
| 4 | update account set balance=2 where id=1; | |
| 5 | select balance from account where id=1;(结果为1) | |
| 6 | commit | |
| 7 | select balance from account where id=1;(结果为2) |
假设我查了下账户余额,看到你们给小编打赏了1块钱,很开心!!!宣布请大家去撸串!!!
在付款之前,钱被另外一个人取走,又查询到没钱了,被留下来洗碗了!!!
因为我查询完后,这条数据没锁住,又被别的事务更新了,导致当前事务每次都是读到最新的数据。

3.3 幻读
在Repeatable Read隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。
事务A读取与搜索条件相匹配的若干行。事务B以插入或删除行等方式来修改事务A的结果集,然后再提交。
举例:
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | Begin | |
| 2 | Begin | |
| 3 | select * from example where id=10;(结果为空) | |
| 4 | insert into example value(10); | |
| 5 | commit | |
| 6 | select balance from account where id=10;(结果为空) | |
| 7 | update example set name=’test’ where id=10 (更新成功) | |
| 8 | select * from example where id=10;(有10这个记录) |
看到了吗,在一个事务A中,第一次查询某条记录,是没有的,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
实际上,在InnoDB引擎中,对于索引的扫描,不仅锁住扫描到的索引,而且还锁住这些索引覆盖的范围(gap),因此这个范围是内插入数据是不允许的。
未完待续…